SEO para LLM: Cómo Funciona la Selección de Contenido en Modelos LLM


Los motores de búsqueda tradicionales organizaban la información mediante enlaces, autoridad y páginas web. Los modelos de lenguaje como ChatGPT funcionan de forma distinta. No buscan páginas ni comparan dominios; generan respuestas analizando patrones del lenguaje, coherencia y factualidad. Para entender por qué una IA selecciona ciertos datos y descarta otros, es necesario comprender cómo procesan el texto internamente y cómo evalúan la claridad y utilidad del contenido. Este cambio marca el paso del SEO basado en enlaces al SEO basado en respuestas.
Las frases corporativas, los mensajes ambiguos y las descripciones genéricas ya no funcionan; ahora gana el contenido que responde rápido, explica después y aporta ejemplos reales.
Sara Solana Pascual
Del SEO de enlaces al SEO de respuestas
El SEO tradicional funcionaba con enlaces, autoridad de dominio y señales externas.
Los LLM como ChatGPT cambian el juego:
- No buscan páginas.
- No comparan enlaces.
- No analizan tu dominio.
- Generan respuestas basadas en: claridad + factualidad + coherencia + utilidad + baja perplejidad.
🟦 En otras palabras
Antes Google decía: “Esta página tiene muchos enlaces ⇒ la muestro.”
Ahora ChatGPT dice: “Este contenido es claro y coherente ⇒ lo uso en mi respuesta.”
🟩 Ejemplo
❌ Mal (texto SEO tradicional): “Somos líderes en soluciones integrales para el sector del mobiliario, con un enfoque 360.”
✅ Bien (texto LLM-SEO): “Vendemos sillas, mesas y estanterías para oficinas.
Envío en 48 horas. Garantía de 2 años.”
Los modelos de lenguaje como ChatGPT no seleccionan información del mismo modo que lo hacen los motores de búsqueda tradicionales. Mientras que Google organiza páginas web mediante sistemas de ranking, un modelo como ChatGPT genera respuestas evaluando la probabilidad de cada token según el contexto del usuario. Para entender por qué ciertos datos aparecen en las respuestas y otros no, es necesario analizar cómo los LLM procesan internamente la información.
La clave está en la arquitectura que utilizan estos modelos para interpretar el prompt, relacionar conceptos y decidir cuál es el siguiente token más probable. Esta arquitectura determina qué fragmentos de información reciben más peso, cómo se combina el contexto y qué datos se consideran relevantes para generar una respuesta útil.
Esa arquitectura se llama Transformer.
Comprender sus principios básicos permite entender cómo un LLM selecciona contenido, cómo filtra información irrelevante y por qué ciertos textos son más fáciles de “extraer” por el modelo que otros. Esto es esencial para cualquier estrategia de SEO orientada a IA, ya que define qué tipo de contenido tiene mayor probabilidad de ser usado en una respuesta generada.
¿Qué son los transformes y cómo seleccionan contenido?
Los Transformers seleccionan tokens según la probabilidad condicionada al contexto.
La herramienta clave es el mecanismo de atención.
¿Cómo funciona la atención?
La Atención (Attention) es el mecanismo que permite a un modelo de lenguaje identificar qué partes del texto son más relevantes para generar el siguiente token.
El modelo compara cada palabra (token) con el resto y calcula qué importancia tiene cada una en el contexto actual.
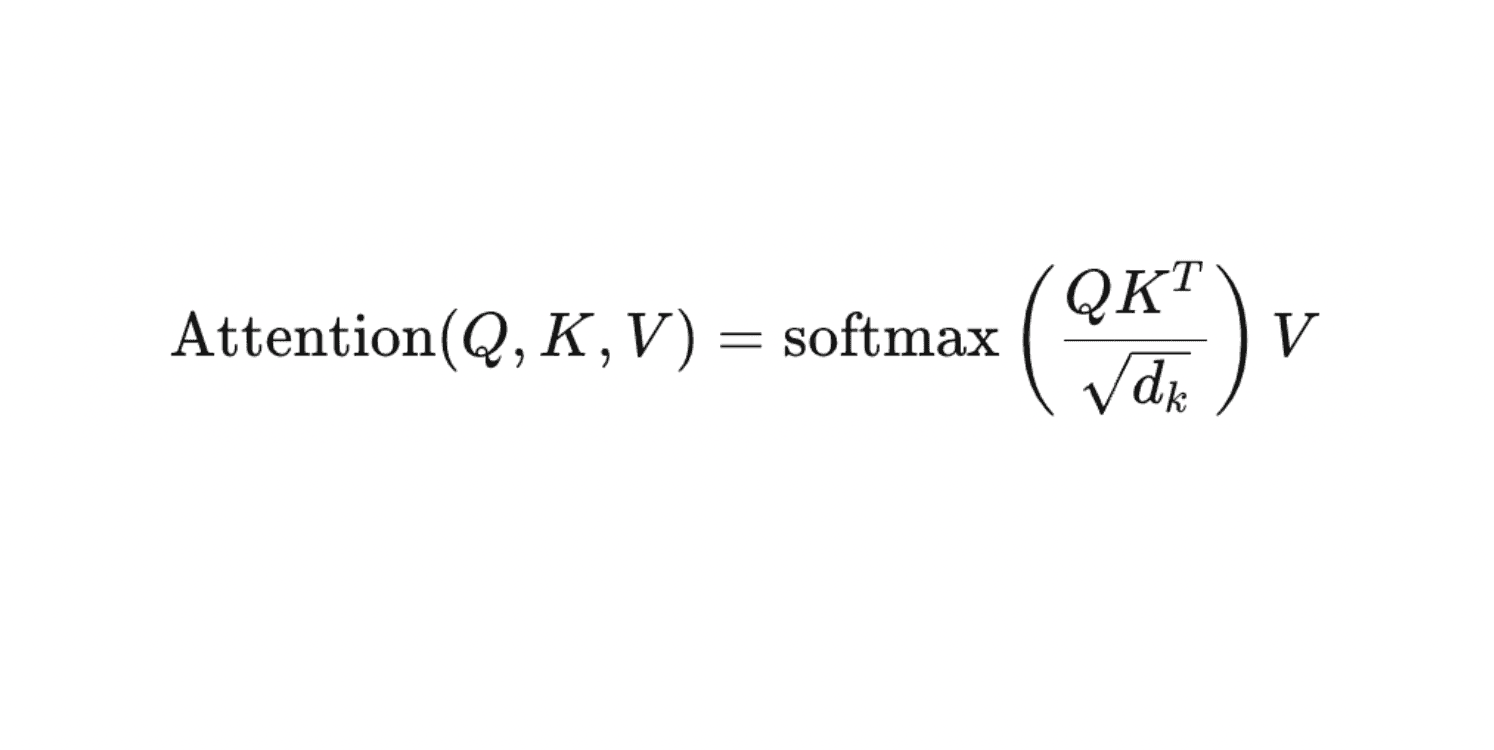
Fórmula del Mecanismo de Atención (Attention Mechanism). Este núcleo de la arquitectura Transformer (LLM) calcula la selección de contenido (tokens) al ponderar las matrices Query ($Q$), Key ($K$) y Value ($V$).
🟦 En términos simples:
La Atención decide “qué mirar” y “cuánto influye” cada palabra en el significado de la frase.
1. Identifica tu consulta (Query).
2. Compara con el contexto (Keys).
3. Decide qué información es relevante (Values).
4. Elige el siguiente token.
🟦 En otras palabras
El modelo decide qué partes del texto son importantes para continuar de forma coherente.
🟩 Ejemplo aplicado a contenido
Consulta:
“¿Cuánto dura una silla de madera?” ❌ Mal (contenido confuso que la IA no selecciona): “La madera es un material noble cuya longevidad depende de factores diversos.”
✅ Bien (contenido que la IA selecciona): “Una silla de madera dura entre 5 y 10 años con uso diario.”
El segundo ejemplo genera baja perplejidad → más seleccionable.
Para entender por qué algunos textos son fáciles de usar para un modelo y otros no, es necesario conocer una métrica clave que mide cuánta claridad percibe la IA en lo que lee. Esa métrica se llama perplejidad.
¿Qué es la perplejidad?
La perplejidad es una métrica estándar en modelos de lenguaje que mide qué tan bien un modelo predice una secuencia de tokens.
Matemáticamente, es la exponencial de la entropía cruzada entre las predicciones del modelo y los datos reales.
Por tanto, “baja perplejidad” significa:
- El modelo asigna altas probabilidades a los tokens correctos y, por tanto, está poco sorprendido por los datos.
- Indica mejor capacidad de predicción y menor incertidumbre.
En otras palabras:
Baja perplejidad = buenas predicciones, baja sorpresa, mayor exactitud.
Alta perplejidad = malas predicciones, mucha sorpresa, baja exactitud.
RLHF ajusta los modelos mediante evaluaciones humanas para que las respuestas sean más coherentes y alineadas con criterios como utilidad y claridad, pero no garantiza una selección perfecta según preferencias humanas. Es un mecanismo de entrenamiento que guía la generación de texto.
¿Qué es RLHF y Cómo la IA aprende qué contenido es bueno?
RLHF (Reinforcement Learning from Human Feedback) es un método para entrenar modelos de lenguaje en el que los humanos proporcionan evaluaciones sobre las respuestas del modelo, y esas evaluaciones se utilizan como señales de recompensa dentro de un algoritmo de aprendizaje por refuerzo.
El objetivo es ajustar el comportamiento del modelo para que produzca respuestas más útiles, seguras y alineadas con las preferencias humanas.
El RLHF refina las respuestas del modelo basándose en:
- utilidad
- claridad
- factualidad
- seguridad
- preferencia humana
- Es el filtro de calidad del modelo.
Una vez que el modelo sabe generar texto coherente, falta un paso clave: aprender qué tipo de respuesta consideramos útil o correcta. Ese aprendizaje guiado por humanos se llama RLHF.
El Modelo de Recompensa (RM)
Un modelo de recompensa es un modelo entrenado para asignar una puntuación a las respuestas generadas por un LLM, basándose en preferencias humanas.
Convierte comparaciones o evaluaciones humanas en una función de recompensa que indica qué respuestas son mejores, más útiles o más seguras.
Es un componente central del proceso RLHF.
Humano ordena respuestas.
El RM aprende ese orden y genera una puntuación:
🟦 En otras palabras
Si tu contenido es el que los humanos elegirían como “mejor”, el RM tenderá a usarlo.
Ejemplo aplicado a contenido
Tarea: “Explica qué es una silla ergonómica”.
- ✅ Respuesta A (clara y útil): “Una silla ergonómica mantiene la espalda recta y reduce la fatiga si trabajas muchas horas sentado.”
- ❌ Respuesta B (vaga): “Las sillas ergonómicas ofrecen una experiencia postural avanzada.”
- ❌ Respuesta C (incorrecta): “Una silla ergonómica corrige automáticamente problemas de columna.”
Los evaluadores prefieren A.
ChatGPT y resto de LLM aprende a reproducir el estilo de A.
El RM indica qué tipo de respuesta prefiere un humano, pero el modelo aún debe aprender a producir ese estilo sin desviarse. Para eso se usa PPO, el método que entrena al LLM a mejorar sin romper su equilibrio interno.
¿Qué es PPO y cómo la IA aprende a evitar errores y mantenerse coherente?
PPO (Proximal Policy Optimization) es un algoritmo de aprendizaje por refuerzo que ajusta los parámetros de un modelo de forma controlada, evitando cambios demasiado grandes en cada actualización.
Su función es mejorar la política del modelo manteniéndola estable y coherente, reduciendo errores y evitando comportamientos impredecibles durante el entrenamiento.
El PPO ajusta el modelo para que:
- genere más contenido con alta recompensa
- no se vuelva errático
- evite inventar cosas
- no se aleje de su base
- Con penalización KL se controla la desviación.
🟦 En otras palabras
PPO es como corregir constantemente al modelo para que mantenga un estilo fiable.
Ejemplo de contenido aplicado
❌ Mal (contenido que el RM penalizaría: “Nuestra silla ergonómica cura dolores de espalda.”
✅ Bien (contenido con buena recompensa): “Nuestra silla ergonómica ayuda a reducir molestias si pasas muchas horas sentado.”
Tras entender cómo PPO ayuda a que el modelo sea coherente y estable, falta responder una pregunta clave: ¿en qué se diferencia un modelo como ChatGPT de un buscador tradicional como Google? Aunque ambos responden preguntas, sus mecanismos internos y el tipo de resultado que producen son completamente distintos.
¿Qué diferencia entre las LLM y Google?
| Aspecto | LLM | |
| Tipo de operación | Recupera documentos indexados en la web. | Genera tokens (palabras) basados en probabilidad. |
| Lógica central | Ranking: ordena páginas según relevancia, autoridad y enlaces. | Generación: predice el siguiente token usando el contexto. |
| Fuente de señales | Enlaces, PageRank, keywords, estructura de página. | Coherencia, factualidad aprendida, patrones del corpus y RLHF. |
| Resultado final | Lista de URLs que contienen la información. | Respuesta directa en lenguaje natural. |
| Unidad de selección | Páginas completas. | Tokens individuales. |
| Dependencia de la web | Dirigirte al mejor documento. | Resolver la consulta con una explicación. |
| Actualización | Reindexación constante de la web. | Actualización por nuevas versiones o fine-tuning. |
🟦 En otras palabras
Google te muestra dónde está la información.
Las LLM te dan directamente la información.
🟩 Ejemplo de contenido
Google: “Aquí tienes 10 páginas sobre sillas de escritorio.”
LLM: “Para una oficina pequeña, una silla ergonómica con respaldo de malla es cómoda y ventila bien.”
Perplejidad: La métrica oculta detrás del nuevo SEO
La perplejidad mide lo difícil que le resulta a un modelo de IA adivinar la siguiente palabra de un texto.
Baja perplejidad → el texto es claro y predecible para la IA.
Alta perplejidad → el texto es confuso o inesperado para la IA.
Es una forma directa de saber qué tan bien entiende y predice lenguaje un modelo.
Perplejidad = qué tan predecible es tu texto para el modelo.
🟦 En otras palabras
A la IA le gusta el contenido “fácil de entender”.
🟩 Ejemplos según nivel de perplejidad
❌ Alta perplejidad: “Nuestra empresa se caracteriza por brindar soluciones innovadoras en el ámbito del mobiliario.”
¿Por qué es mala?
- Ambigua
- No describe nada
- No es factual
- No responde a ninguna intención
✅ Baja perplejidad
“Vendemos sillas de oficina con respaldo de malla y soporte lumbar.
Entrega en 48 horas.”
¿Por qué es buena?
- Clara
- Factual
- Concreta
- Reutilizable por la IA
“Frases más claras y concretas suelen ser más fáciles de generar para la IA, porque presentan baja perplejidad, pero esto no significa que la IA seleccione activamente estos textos de la web.”
Una vez que entendemos cómo las LLM se diferencian de Google —porque no buscan páginas, sino que generan lenguaje— aparece una métrica clave para optimizar contenido en esta nueva lógica: la perplejidad. Es la forma en que un modelo mide lo fácil o difícil que le resulta predecir tu texto.
El nuevo SEO: ¿Cómo debe escribirse el contenido ahora?
El SEO moderno debe centrarse en crear contenido que un LLM quiera seleccionar.
Los pilares clave:
- Contenido directo y factual
- Respuestas cortas al inicio
- Explicaciones desarrolladas después
- Ejemplos concretos
- Lenguaje natural
- Formato pregunta/respuesta
- Dato verificable
A continuación vienen ejemplos completos de cómo debe ser el contenido según la parte del artículo.
Ejemplos reales de cómo escribir para LLM-SEO
Ejemplo 1: Definición
❌ Mal: “Las sillas ergonómicas son soluciones avanzadas para mejorar la postura corporativa.”
✅ Bien: Una silla ergonómica es una silla diseñada para mantener la espalda recta y reducir la fatiga durante largas horas de trabajo.
Este es el tipo de texto que un LLM selecciona.
Ejemplo 2: Explicación técnica
❌ Mal: “El poliéster es un material multifacético utilizado en muchos contextos.”
✅ Bien: Qué es el poliéster:
El poliéster es un material resistente y fácil de limpiar.
En muebles se usa porque soporta el uso diario sin desgastarse rápido.
Ejemplo 3: Comparación
❌ Mal: “La madera y el metal son materiales distintos con propiedades únicas.”
✅ Bien: Madera vs metal en mesas:La madera es cálida y estética.
El metal es más resistente a golpes y humedad.
Para oficinas pequeñas, el metal suele durar más.
Ejemplo 4: Responder una pregunta
❌ Mal: “La durabilidad depende de muchos factores.”
✅ Bien: ¿Cuánto dura una mesa de oficina?
Una mesa de oficina dura entre 5 y 12 años según el material y el uso diario.
Ejemplo 5: Instrucción “How-To”
❌ Mal: “Es importante elegir la silla adecuada según tus necesidades.”
✅ Bien: Cómo elegir una silla: Elige respaldo de malla si trabajas más de 6 horas.
Fíjate en el soporte lumbar.
Asegúrate de que los reposabrazos sean ajustables.
Tu contenido compite por ser la respuesta de la IA, no por un ranking
La clave del SEO moderno es producir contenido:
- claro
- estructurado
- directo
- verificable
- con ejemplos
- con respuestas inmediatas
- con baja perplejidad
👉 Tu misión no es posicionar una página.
👉 Tu misión es convertir tu contenido en la mejor respuesta posible para un LLM.
Qué deben hacer ahora las empresas ante el nuevo SEO basado en respuestas
La transición del SEO tradicional al SEO orientado a modelos de lenguaje cambia por completo la forma en la que las empresas deben crear contenido. Durante años, la visibilidad dependía de enlaces, autoridad de dominio y optimización técnica. Hoy, los modelos como ChatGPT no ven nada de eso: solo ven el texto.
Los modelos de lenguaje como ChatGPT generan texto basándose en la probabilidad de cada token según el contexto, sin buscar páginas web ni comparar dominios. Factores como coherencia, claridad y patrones aprendidos durante el entrenamiento influyen en la calidad de la respuesta, pero no existe un proceso explícito de “selección” de contenido externo.
Para seguir siendo relevantes, las empresas necesitan reescribir su contenido pensando en cómo razonan los LLM. El objetivo ya no es posicionar páginas, sino generar textos que el modelo pueda usar directamente para responder. Esto implica escribir de forma más simple, concreta y verificable.
La autoridad deja de ser un atajo. Un dominio con gran reputación no tiene ventaja si sus textos no son claros. Cualquier competidor puede adelantarlo simplemente creando contenido directo, comprensible y útil. En este escenario, las empresas deben centrarse en producir textos que un modelo de IA pueda entender sin esfuerzo: definiciones claras, comparaciones simples, pasos concretos, datos verificables y ejemplos aplicados a casos reales.
El nuevo SEO exige pensar en cómo un LLM selecciona tokens, filtra ruido y premia contenido con baja perplejidad. Cada página debe estar diseñada para ser una respuesta lista para usar. La misión ya no es escalar posiciones, sino convertirse en la mejor opción para que un modelo de lenguaje la incluya en su salida. En un entorno donde la IA genera la respuesta final, tu contenido compite por ser el fragmento más útil, no por un lugar en un ranking.
Las empresas que adapten su contenido a este nuevo paradigma tendrán una ventaja decisiva. Las que sigan escribiendo como antes desaparecerán de las respuestas generadas por IA. El futuro del SEO no está en los enlaces, sino en crear información tan clara y útil que un modelo de lenguaje la quiera elegir. Tu contenido ya no compite por una página: compite por ser la respuesta.